sql增删改查语句怎么写,sql增删改查语法
一、初识数据库
DBMS主要通过数据的保存格式(数据库的种类)来进行分类,现阶段主要有以下5种类型:
层次数据库(Hierarchical Database,HDB); 关系数据库(Relational Database,RDB),如Oracle Database、SQL Server、MySQL等; 面向对象数据库(Object Oriented Database,OODB); XML数据库(XML Database,XMLDB); 键值存储系统(Key-Value Store,KVS),如MongoDB;
1.2 RDBMS的常见系统结
使用RDBMS时,最常见的系统结构是客户端/服务器类型(C/S类型),如下:

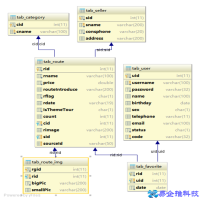
数据库中存储的表结构类似于excel中的行和列,在数据库中,行称为记录,它相当于一条记录;列称为字段,它代表了表中存储的数据项目;行和列交汇的地方称为单元格,一个单元格中只能输入一条记录。

DDL(数据定义语言):用于创建和重构数据库对象,如创建和删除表;其指令有CREATE(创建数据库和表等)、DROP(删除数据库和表等)、ALTER(修改数据库和表等); DML(数据操作语言):用于操作关系型数据库对象内部的数据;其指令有INSERT(向表中插入新数据)、UPDATE(更新表中的数据)、DELETE(删除表中的数据); DQL(数据查询语言):用于构成对关系型数据库的查询;其指令有SELECT(查询表中的数据)、其可与count/sum/group by/order by/having等组合在一起使用; DCL(数据控制语言):用于创建与用户访问相关的对象,以及控制用户的权限;其指令有COMMIT(保存数据库事务)、ROLLBACK(撤销数据库事务)、GRANT(赋予用户操作权限)、REVOKE(取消用户的操作权限);
二、增删改查
数据库创建的表,所有的列都必须指定数据类型,每一列都不能存储与该列数据类型不符的数据。
CHAR型:用来存储定长字符串,当列中存储的字符串长度达不到最大长度的时候,使用半角空格进行补足,由于会浪费存储空间,所以一般不使用; VARCHAR型:用来存储可变长度字符串,定长字符串在字符数未达到最大长度时会用半角空格补足,但可变长字符串不同,即使字符数未达到最大长度,也不会用半角空格补足; INTEGER型:用来指定存储整数的列的数据类型(数字型),不能存储小数; DATE型:用来指定存储日期(年月日)的列的数据类型(日期型); 此外,还有bigint、float、datetime、year等;
NOT NULL:是非空约束,即该列必须输入数据; PRIMARY KEY:是主键约束,代表该列是唯一值,可通过该列取出特定的行的数据;
(< 列名1 > < 数据类型 > < 该列所需约束 >,
< 列名2 > < 数据类型 > < 该列所需约束 >,
< 列名3 > < 数据类型 > < 该列所需约束 >,
< 列名4 > < 数据类型 > < 该列所需约束 >,
......
< 该表的约束1 >, < 该表的约束2 >, ......);
删除列:ALTER TABLE < 表名 > DROP COLUMN < 列名 >;
TRUNCATE TABLE < 表名 > ;
DROP TABLE < 表名 > ;
(列1, 列2, 列3,......) -- 若全列插入,此语句可省略
VALUES(值1, 值2, 值3,......);
INSERT INTO < 表名 >
(列1, 列2, 列3,......) -- 若全列插入,此语句可省略
select < 需要的列名 >
from < 要查询的表 >;
where condition -- 可选;
SET < 列名 > = < 表达式 > [,< 列名2 > = < 表达式2 >...];
WHERE condition; -- 可选
ORDER BY 子句; --可选
LIMIT 子句; --可选
FROM < 表名 >
where condition -- 可选
oeder by 某列名 -- 可选
where condition
三、操作符和聚合函数
操作符是一个保留字或字符,主要用于SQL语句的where子句来执行操作,其和python中的运算符基本一致。
算术运算符:加减乘除( + - * / );
比较运算符:等于、不等于、大于、小于、大于等于等(=、<>或!=、 >、<、>=、<=);
逻辑运算符:between、is null、like、in、all、any、is not null、not in等;
连接运算符:and(且,交集)、or(或,并集);
聚合函数也叫汇合函数,其为SQL语句提供合计信息,如计数、总和、平均等。
COUNT函数:一般用于统计不包含null值的记录数(行数),如count(col_name);但count(*)会统计表中全部记录数,包含null和重复值;可与`distinct`一起使用(去重);
SUM函数:返回某字段的总和;可与`distinct`一起使用,这时只会计算不同记录的和,一般无意义,可忽略;只适用于数值类型的列;
AVG函数:返回某字段的平均值;可与distinct一起使用,这时只会计算不同记录的平均值,一般无意义,可忽略;只适用于数值类型的列;
MAX函数:返回某字段的最大值,null值不在计算范围之内;适用于所有数据类型;
MIN函数:返回某字段的最小值,null值不在计算范围之内;适用于所有数据类型;
四、数据排序和分组
数据分组是按照逻辑次序把具有重复值的字段进行合并;其是通过在select语句里使用group by子句来实现。
排序用于对查询得到的数据进行排序,用order by子句来实现(默认升序(即asc),降序为desc)。
SELECT < 列1 >,< 列2 >,< 列3 >,...
FROM < 表名 >
GROUP BY < 列1 >,< 列2 >,< 列3 >,...
ORDER BY < 列m >[asc/desc], < 列n >[asc/desc], ...
书写顺序:SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY
五、练习题

# 创建表create table addressbook(regist_no INTEGER NOT NULL COMMENT '注册编号',name VARCHAR(128) NOT NULL COMMENT '姓名',address VARCHAR(256) NOT NULL COMMENT '地址',tel_no CHAR(10) COMMENT '电话号码',mail_address CHAR(20) COMMENT '邮箱地址',PRIMARY KEY (regist_no)); # postal_code、定长字符串类型(长度为8)、不能为 NULLALTER TABLE addressbook ADD COLUMN postal_code char(8) NOT NULL COMMENT '邮政编码' # 删除 addressbook DROP TABLE addressbook '删除掉的addressbook表,不能恢复,只能重新创建'

本文地址:百科问答频道 https://www.neebe.cn/wenda/903129.html,易企推百科一个免费的知识分享平台,本站部分文章来网络分享,本着互联网分享的精神,如有涉及到您的权益,请联系我们删除,谢谢!

 相关阅读
相关阅读