python网络爬虫基础教程(python网络爬虫0基础入门详细介绍)。爬虫不一定要用python,也可以用java和C,但是python是所有编程中最好上手的
robots.txt协议:君子协议,规定了网络中哪些数据可以被爬取数据,哪些不可以
爬虫:通过编写程序来获取网络上的资源
什么是url
URL是统一资源定位符,对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎处理它。
URL由两个主要的部分构成:协议(Protocol)和目的地(Destination)。
“协议”是告诉我们自己面对的是何种类型的Internet资源。
web中最常见的协议是http,它表示从Web中取回的是HTML文档。其他协议还有gopher,ftp和telnet等。
目的地可以是某个文件名、目录名或者某台计算机的名称。
第一个爬虫
")
由于各大网站反爬虫的防护做的还是相当可以的,所以这样的基础代码只能算是一个小尝试,并不能拿来应用。
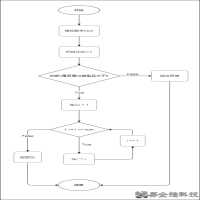
Web请求过程剖析
服务器渲染
在服务器那边直接把数据和html整合在一起,统一返回给浏览器,在页面源代码中能看到数据
客户端渲染
第一次请求只要一个html骨架,第二次请求拿到数据,进行数据展示,在页面源代码中看不到数据
HTTP协议
协议:两个电脑传输数据时进行的君子约定
HTTP全称Hyper Text Transfer Protocol(超文本传输协议),浏览器和服务器之间数据交互遵守的是HTTP协议
HTTP不论是请求还是响应都是三块内容
")
请求头中常见的一些内容(爬虫需要):
User-Agent:请求载体的身份标识(用什么发送的请求)
Referer:防盗链(此次请求是从哪个页面来的)
cookie:本地字符串数据信息(用户登录信息,反爬的token)
Requests
Request模块需要额外安装
案例一(get方式)
")
")
从运行结果可以看出,网页给出了响应,但是明显制止了程序的爬虫操作。为了能够逃过网页的监视,我们要为自己设置一个浏览器身份。
网页鼠标右键点击检查,并进入网络,刷新一下便出现了如下页面。
")
往下翻看,可以看到一个User-Agent,这是网页所显示的访问的浏览器身份,我们将它复制。
")
代码更改如下:

")
此刻便如愿爬取了网页的源代码
案例二(post方式)
我们用post方式来发送请求,想要获取什么就在右边寻找对应的文件,此时我想要获取蓝色圈住的这些数据,于是我找到了sug文件,并查看它的url。
")
我们将url赋值给代码的数据,并设置字典来保存我们想要查询的数据
")
![]()
post请求一个数据,网页返回了这个单词的意思,就像python的一个字典一样
发送post的请求必须放在字典中,并用data传递数据
get与post的区别
通过以上两个案例我们可以看到get请求方式仅仅是获取浏览器的数据,称为“显式访问”,而post在访问的时候会发送一个数据,比如上述案例的百度翻译原本我们想要查到的是dog的翻译,post方式发送了mun单词,最后我们获取到了mun的汉语意思,这称为“隐式访问”
案例三
XHR:第二次请求数据
")
![]()
我们寻找浏览器可以进入的User-Agent,并输入
")
")
如愿爬取到了信息,但是此时我们看起来不是很方便,转为json换成我们更熟悉的文件。
")
爬取完信息一定要记得关掉访问,不然会被反爬盯上
本文地址:百科问答频道 https://www.neebe.cn/wenda/886664.html,易企推百科一个免费的知识分享平台,本站部分文章来网络分享,本着互联网分享的精神,如有涉及到您的权益,请联系我们删除,谢谢!

 相关阅读
相关阅读